-
AI FactoryAI FactoryAI Factory – already hereThe AI Factory is no longer a concept — it’s a reality.

-
NeoCloudNeoCloudAI Factory – already hereThe AI Factory is no longer a concept — it’s a reality.
-
SolutionsSolutions
-
CompanyCompany



AI and ML Inference
Maximize accuracy and speed for seamless integration into your systems
Scalable and high-performance results
01
Built on Industry-Proven Technologies
Leverage a battle-tested AI infrastructure with Kubernetes, Kubeflow, KServe, Triton, and vLLM. Whether deploying transformers for inference or managing complex ML pipelines, our platform ensures scalability, flexibility, and performance without vendor lock-in.
02
Secure and Compliant AI Inference
Keep your AI operations fully private with isolated environments, strict access controls, and compliance-ready infrastructure. Your models and data stay fully sovereign, ensuring regulatory compliance and enterprise security.
03
Real-Time Monitoring and Observability
Gain full visibility into model performance with real-time inference monitoring, logging, and alerting. Integrate with Prometheus, Grafana, and OpenTelemetry to track response times, accuracy drift, and resource utilization.
04
Seamless Deployment for LLM-Powered Applications
Easily integrate and deploy your LLM-powered applications with LangChain, LangSmith, LangFuse, Orq.ai, and more. Whether you’re building AI agents, RAG pipelines, or enterprise chatbots, our infrastructure is optimized for seamless development and deployment.
Maximize efficiency with top ML Inference Performance
5
sec
Maximum time setting up your cluster
100
Gb/s
The speed of the internet connection in our data center
Leverage advanced AI and ML inference
All for real-time, data-driven decision-making.
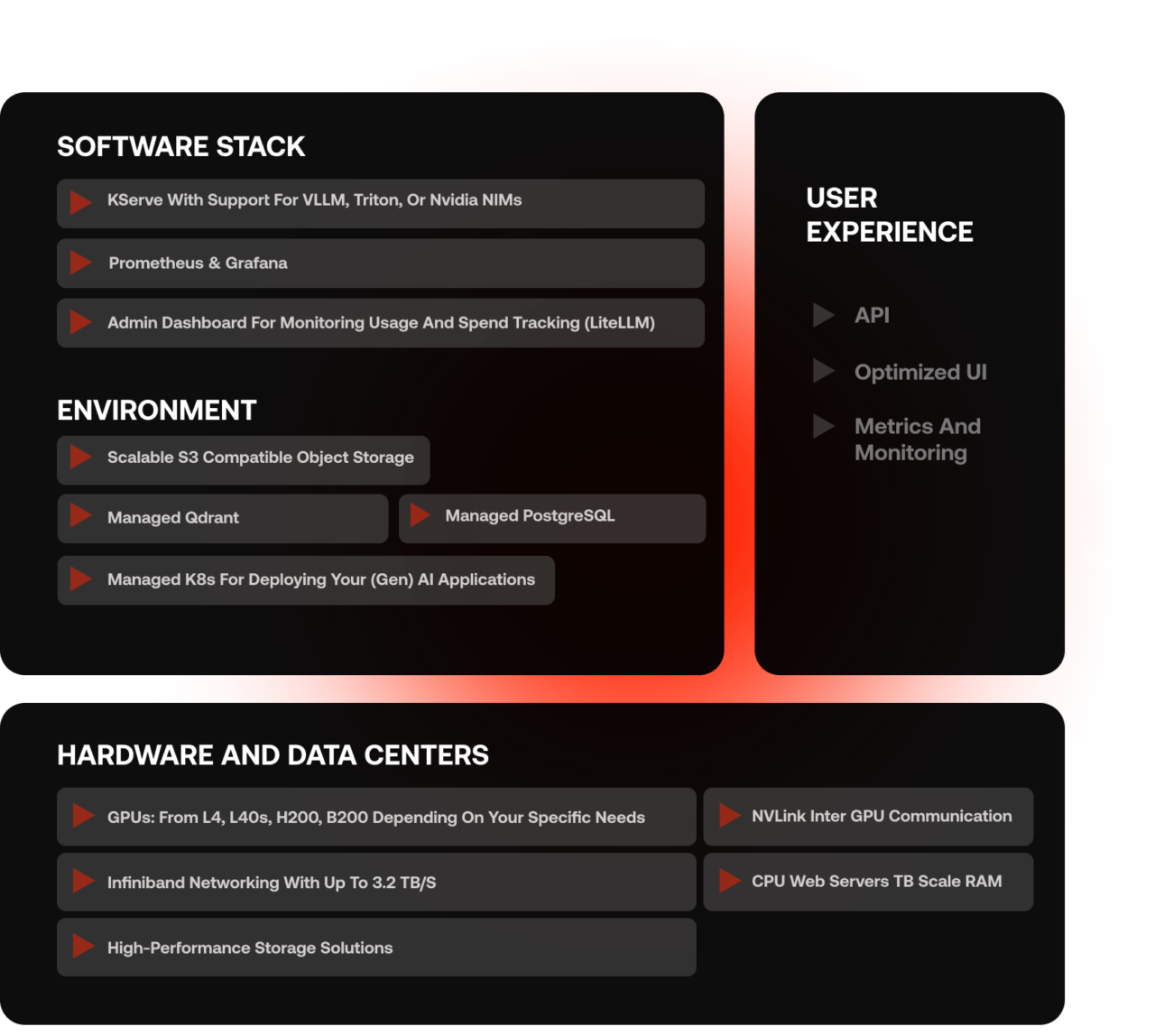
Private AI full stack support
Tailor AI/ML models to your specific needs with full-stack support, including seamless partner integrations, a robust ecosystem, scalable infrastructure, and powerful hardware for optimal performance and flexibility.
100% European, 100% Private
Deploy AI and get results
without the risks
Become a member of a select group of leaders.